



Neuroscientist Paul Thompson (left) with computer scientist Greg Ver Steeg. (Photo/Caitlin Dawson.)
Nearly 50 million people worldwide have Alzheimer’s disease or another form of dementia. While age is the greatest risk factor for developing the disease, researchers believe most Alzheimer’s cases occur as a result of complex interactions among genes and other factors. But those factors and the role they play are not known—yet.
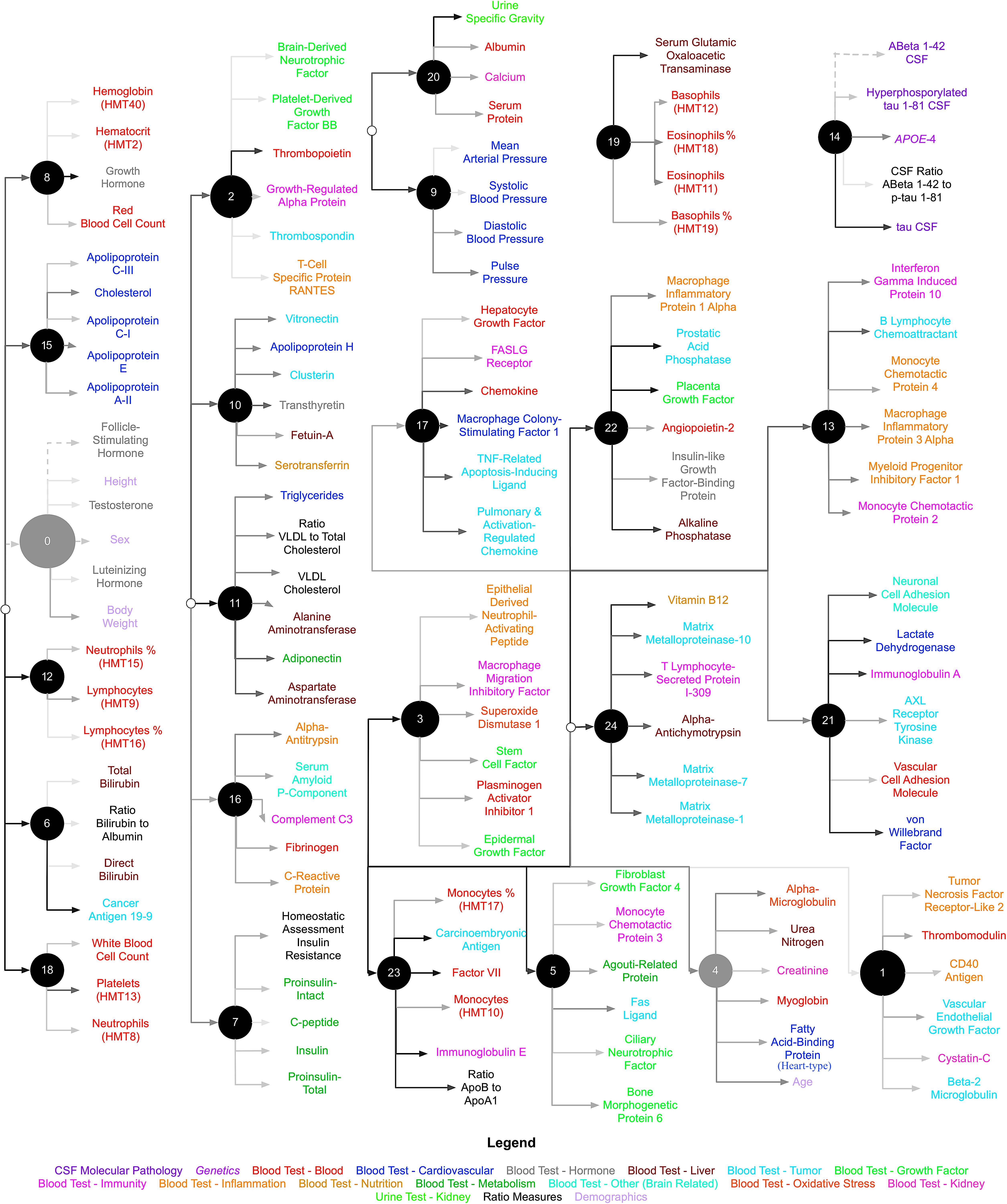
In a new study, USC researchers used machine learning to identify potential blood-based markers of Alzheimer’s disease that could help with earlier diagnosis and lead to non-invasive ways of tracking the progress of the disease in patients. The method was developed by USC computer science research assistant professor Greg Ver Steeg, a senior research lead at the USC Information Sciences Institute (ISI). Machine learning is a subset of artificial intelligence (AI) that gives computers the ability to learn without being explicitly programmed.
“This type of analysis is a novel way of discovering patterns of data to identify key diagnostic markers of disease.” Paul Thompson.
“This type of analysis is a novel way of discovering patterns of data to identify key diagnostic markers of disease,” said team member Paul Thompson, the associate director of the USC Mark and Mary Stevens Neuroimaging and Informatics Institute and professor in the Keck School of Medicine at USC. “In a very large database of health measures, it helped us discover predictive features of Alzheimer’s disease that nobody suspected were there.”
The study, “Uncovering Biologically Coherent Peripheral Signatures of Health and Risk for Alzheimer’s Disease in the Aging Brain,” appeared in Frontiers in Aging Neuroscience, Nov. 28. The study authors are from the USC Mark and Mary Stevens Neuroimaging and Informatics Institute and the USC Information Sciences Institute.
Identifying biomarkers
While most Alzheimer’s research to date has focused on known hypotheses, such as the build up of amyloid plaque and tau protein in the brain, both measures have proved tricky to measure in the bloodstream.
As such, diagnostic tests are largely based on memory. Unfortunately, by the time a person starts showing signs of memory loss, they may have already had the disease for decades. Catching the disease early, before symptoms even appear, is a crucial step in managing the disease with drugs and lifestyle changes that can improve quality of life.
As a result, neuroscientists at USC wondered if there could be other “hidden” indicators of Alzheimer’s—factors that could be detected with a routine blood test. But how do you find something when you don’t know what you’re looking for?

Greg Ver Steeg (left) and Paul Thompson, pictured with USC neuroscience student Joanna Bright, who is researching Parkinson’s disease. Thompson hopes to use Ver Steeg’s machine learning method to find hidden factors in other brain diseases, in addition to Alzheimer’s. (Photo/Caitlin Dawson).
So, they turned their attention towards machine learning, enlisting the expertise of Greg Ver Steeg, a USC computer scientist and physicist who specializes in mining complex data.
In 2013, Ver Steeg developed an advanced machine learning method called Correlation Explanation (CorEx) capable of teasing out patterns in areas often overwhelmed by large amounts of data, including neuroscience, psychology and finance. The same year, the method made the news when Shirley Pepke, a computational biologist at Caltech, used the algorithm to study her own cancer.
In this particular study, the scientists’ goal was to use the same algorithm to unearth hidden factors—or clusters of related factors—in medical data that could be correlated with Alzheimer’s disease.
“It could be that there is no single predictor of whether you are likely to have cognitive decline, if it’s begun already, or how severe it’s going to be,” said Ver Steeg. “But maybe there’s collections of indicators that would be a better signal. The question we were looking at was whether we could use the algorithm to find groups of features that could be a better predictor of Alzheimer’s than any factors measured individually.”
Clusters of relationships
The researchers examined medical data collected from 829 older adults from the Alzheimer’s Disease Neuroimaging Initiative database to identify predictors of cognitive decline and brain atrophy over a one-year period.
Participants fell into three diagnostic categories: cognitively normal, mild cognitive impairment and those with Alzheimer’s disease. The data included more than 400 biomarkers collected from brain imaging, genetics, plasma, and demographic information.
Sure enough, when the scientists ran the data through Ver Steeg’s algorithm, distinct clusters of relationships emerged. Amyloid and tau were found to be important, but the algorithm also revealed strong relationships with cardiovascular health, hormone levels, metabolism and immune system response. For instance, low vitamin B12 levels, which can be a risk factor in cardiovascular disease, were grouped together with enzymes called matrix metalloproteinases, also characteristic of cardiovascular diseases, and a protein secreted by T-cells, known to participate in immune response.
While the relationships between some of the measures had been previously documented and were known to be associated with Alzheimer’s, “the results points to a synergy between features being a stronger predictor than individual features,” said Thompson.
“Maybe fixing one of these things alone doesn’t make a huge difference, but fixing a cluster of things could be helpful in reducing the risk of developing the disease.”
A growing list of biomarkers could lead to earlier diagnosis and better prognosis, providing new targets for blood tests, said Thompson. In future studies, he and his team hope to confirm the results in a larger population of patients and use Ver Steeg’s method to find hidden factors in other diseases, such as schizophrenia and depression.
Published on January 28th, 2019
Last updated on November 15th, 2022








{kind=link}