



(ART/SHUTIANYI LI)
“When will the pandemic end?” is the trillion-dollar question of 2020.
Data scientists have become unlikely heroes we are relying on for at least a hint to the answer. Their wave-shaped COVID-19 models that present “best” and “worst-case” scenarios for the virus trajectory are popping up everywhere in news stories and on screens behind governors during press conferences. But as the graphs get more sophisticated and the virus surges and recedes, one thing has become increasingly clear: coronavirus models aren’t crystal balls. So, what are they good for?
Enter USC Viterbi professors Vasilis Marmarelis, Viktor Prasanna and Ajitesh Srivastava.
They understand that going from massive, sophisticated data to accurate and reliable epidemic forecasts is not only about choosing or developing the right model, but also about many decisions that go into data pre-processing, model simplification and learnability in artificial intelligence applications. In other words, the easier these models become to read and interpret, the better the decision-making and the more lives saved.
On October 15th, Marmarelis, Dean’s Professor of Biomedical Engineering and founder of USC’s Biomedical Simulations Resource (BMSR), together with Prasanna, Charles Lee Powell Chair in Engineering in the Ming Hsieh Department of Electrical and Computer Engineering who leads the Data Science Lab; and Srivastava, a senior research associate in the Data Science Lab, gave a lecture on how decisions makers can overcome the challenges of epidemic forecasting using novel approaches developed by each.
This fall, following the National Academy of Engineering (NAE) Call to Action for engineers to “crowdsource and collectively brainstorm engineering solutions for COVID-19” USC Viterbi is offering “Viterbi vs. Pandemics!,” a new lecture series by USC Viterbi faculty to comprehensively provide an engineering-centric framework for addressing and understanding the pandemic.
During the 10-week, free program, students gain exposure to myriad topics, ranging from the estimation of risk and protein engineering by directed evolution to the contributions made by computer science and electrical engineering faculty in automating human safety technologies, detecting misinformation and digital contact tracing. The one- to two-hour sessions take place on Thursdays at 6 p.m.
We caught up with Marmarelis and Srivastava as they zoomed out of their virtual “Viterbi vs. Pandemics” lecture back to work on their timely research.
For those who missed it, can you briefly summarize your lecture for a general audience?
(V.M.) Using a mathematical equation introduced three centuries ago by the Italian mathematician Jacopo Riccati to describe the time-course of infectious processes within an isolated community (something we refer to as an “infection pool”), my lecture presented an adaptive statistical methodology that extracts from time-series data possible “cascaded infection waves.” These occur through multiple interconnected infection pools, whereby each infection wave is represented by a Riccati equation (module) with coefficients estimated adaptively from the data. The extracted concatenated – or linked – Riccati modules constitute a predictive model of the dynamics of the infectious process and an insightful decomposition of its time-course. We applied this approach to the time-course of daily confirmed COVID-19 cases in the U.S. and revealed some useful insights and actionable predictions to assist policy makers in their decision-making process.
(A.S.) We covered the challenges in going from data to forecasting and emphasized that “modeling” is just a small part of generating forecasts in the lectures. I presented a fundamental issue in “learning,” which asks whether the parameters of a model can be reliably learned from the given data. I introduced a modeling approach that can capture various complexities and yet be mathematically simplified to ensure the model can be reliably learned. From that, I demonstrated that simple decisions in data pre-processing can potentially have higher impact than the choice of modeling itself.
Why is this research important? How will it help in the fight against COVID-19?
(V.M.) It can be a very valuable resource in the hands of decision-makers enacting policies as we speak. It can also reveal valuable insights into the dynamic structure of the epidemic process vis-a-vis applied policies, such as are certain policies more effective than others. It also offers a quantitative tool to compare the structural decompositions of the epidemic time-course in different countries, American states or local communities, in relation to their policies.
(A.S.) Forecasting is a vital aspect of resource management and policy making. With a plethora of research emerging in epidemic forecasting, it is essential to understand what decisions result in good forecasts and regularly comparing against forecasts performed by others. Professor Viktor Prasanna and I are meeting with the C.D.C. weekly along with more than 30 research teams that are submitting forecasts to the C.D.C. Based on these forecasts, the C.D.C. generates reports describing where we may be heading in the near future and which states may be expected to show severe breakouts. These forecasts are also being used to plan vaccine trials.
How would you compare your research to similar research?
(A.S.) Many modeling strategies attempt to forecast by having complex models that can potentially cover many aspects of the pandemic. Such models are prone to overfitting, i.e., they can fit very well to previously seen data, but may not produce accurate forecasts. Instead, we start with a complex model and simplify it to ensure we avoid overfitting. Among the many different approaches being used to generate forecasts for the C.D.C., we have observed that the simpler models have indeed performed the best compared to complicated models.
(V.M.) This is an entirely different approach than the ones that are commonly used, which are primarily variants of the SIR-class of models, first introduced about a century ago and adapted to various sophisticated forms for specific purposes, or linear autoregressive-type models.
What are the next steps and/or milestones in terms of your work?
(V.M.) We hope to analyze data from multiple countries or U.S. states and compare the results with their respective policies applied in each case. An important future extension also pertains to the dynamic relation between “confirmed COVID cases” and “confirmed COVID deaths” in each country as a quantitative measure of the efficacy of the respective health-care system.
(A.S.) We are building a platform for the artifice intelligence-machine learning community so that a proper comparison of the forecasting methodologies can be performed, and insights can be drawn to understand the critical decisions about modeling and beyond, that affect the accuracy.
Tell us about your collaborators. How have you all faired working remotely?
(V.M.) I am looking forward to more collaborations in the near future. So far, this work has been done in the old-fashioned tradition of “solitary scholarship” with occasional discussions with colleagues on general related issues.
(A.S.) For us, the regular meetings with the C.D.C. have kept us on track regarding the forecasting needs and evaluation metrics.
Can you share one story from your life during lockdown? How has it impacted your work and family? What are you doing to stay sane?
(V.M.) My family and I are grateful to remain safe and enjoy each other’s company. We have multiple lively discussions on a broad range of issues while working from home. I find that creative work is the best remedy for the strains of this self-imposed “home confinement.” An interesting historical note: Isaac Newton developed the “Differential Calculus” during the confinement of the plague in England of his time. I have always been intrigued by the fact that even in horrible circumstances, and this pandemic certainly qualifies as such, some “good” developments materialize because the creative forces within us are stimulated to counter the imposed strains, as long as we remain safe.
(A.S.) I am fortunate to have a job that hasn’t been as affected by the pandemic as much as many other jobs. While working virtually does save time, it can also have negative health impacts. To ensure sanity and health while being restricted to staying home, I built a 12-foot-tall adjustable free-standing rock-climbing wall in my backyard. Whether taking such laborious task during the heat of August is a sign of sanity is up for debate.
What do you consider the most surprising or counter intuitive aspect of the virus or the pandemic as a whole?
(V.M.) One of the most peculiar – and still largely unexplained – phenomena I observed is that of “happy hypoxemia” that has killed many unfortunate hospitalized COVID patients especially in the initial phase of the pandemic. Normally, a drop in blood oxygen will set in motion several autoregulatory or homeostatic mechanisms that do not seem to be activated in some serious COVID cases. I am investigating this intriguing problem in my other research activities that pertain to the homeostatic cardio-respiratory regulation of tissue oxygenation.
If you could only share one slide from your lecture, what would it be and why?
(V.M.) The slide below that shows the decomposition of the time-course of COVID daily cases in the U.S. into 7 infection waves from March 11, 2020 to October 14, 2020. It demonstrates the serious impact of premature and rapid removal of mitigation policies after the first 3 infection waves in mid-May (around Day 70 in the plot). Note the two large components peaking around Day 130 and the two still-rising components on the right of the plot caused by this.

Courtesy of Vasilis Marmarelis
(A.S.) My favorite slide is “The Applied M.L. Anthem: Many can fit, some can forecast, and few/none reveal the truth”. An approach can fit the past very well and yet fail to forecast accurately. On the other hand, an approach that forecasts accurately does not necessarily mean it is able to correctly estimate some underlying truth. The distinction between fitting, forecasting, and correctly estimating the underlying truth using an algorithm must be made clear in applied A.I./M.L. research.
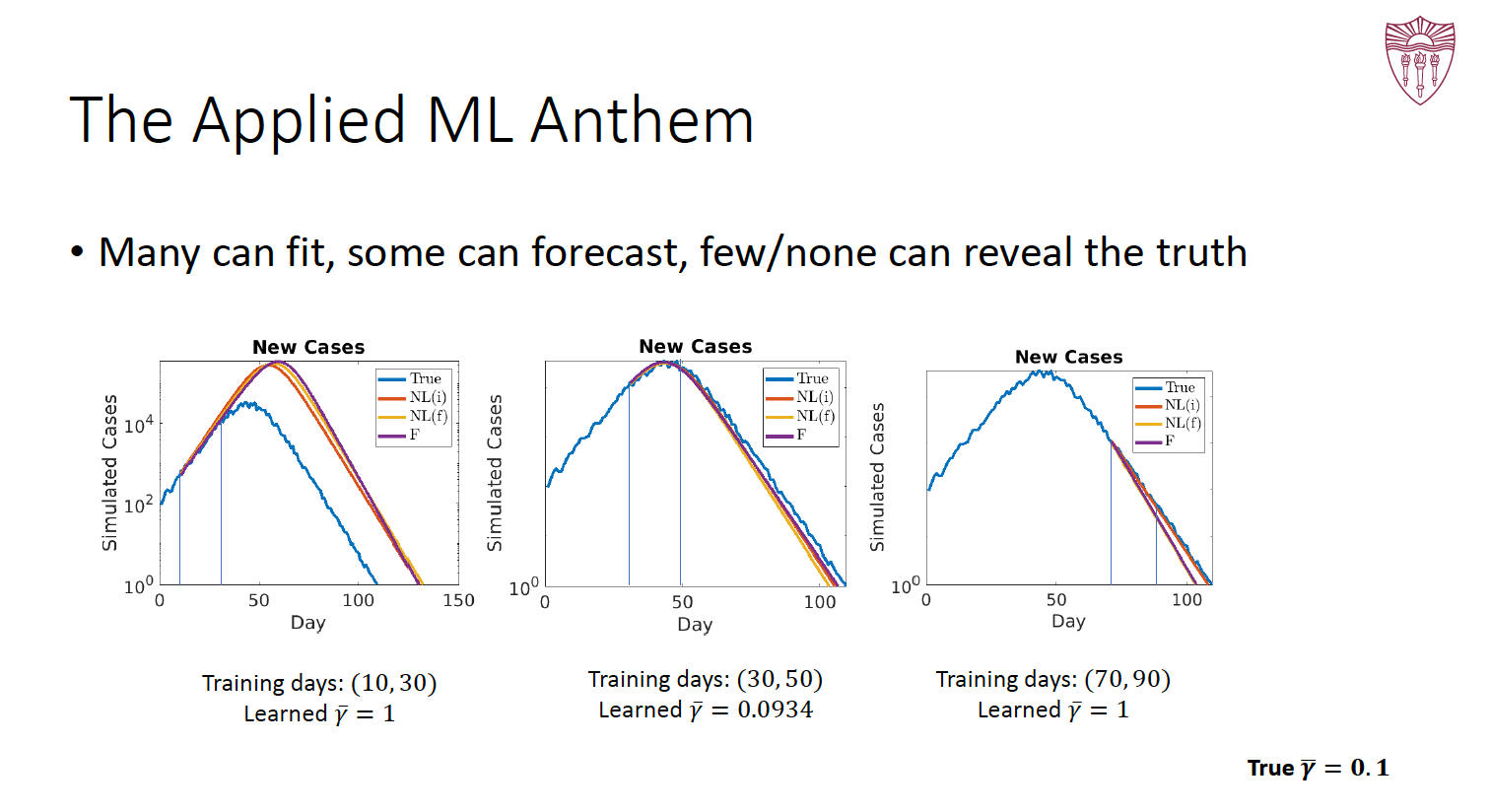
Courtesy of Viktor Prasanna and Ajitesh Srivastava
Related Papers:
Ajitesh Srivastava, Tianjian Xu and Viktor K. Prasanna, “Fast and Accurate Forecasting of COVID-19 Deaths using the SIkJalpha Model”. Preprint: https://arxiv.org/abs/2007.05180
Ajitesh Srivastava and Viktor K. Prasanna, “Data-driven Identification of Number of Unreported Cases for COVID-19: Bounds and Limitations”. ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Health Day Track (KDD 2020). https://arxiv.org/abs/2006.02127
Ajitesh Srivastava and Viktor K. Prasanna, “Learning to Forecast and Forecasting to Learn from the COVID-19 Pandemic”. Preprint: https://arxiv.org/abs/2004.11372
Vasilis Z. Marmarelis “Predictive Modeling of Covid-19 Data in the US: Adaptive Phase-Space Approach”
Published on October 23rd, 2020
Last updated on May 19th, 2023






