


Almost since they were first invented, the reconfigurable computing platforms called “Field Programmable Gate Arrays” have had a reputation: “Good idea in theory, but…” Now, a University of Southern California computer scientist says two advances her team will report June 4 “will kick a lot of ‘but,'” and help to bring FPGAs into the computing mainstream.
“Theoretically, FPGAs combine the speed of dedicated, application-optimized hardware with the ability to flexibly change chip resource allocation, so the same system can run many applications, optimized for each one,” explains Mary Hall, a project leader at USC’s Information Sciences Institute and research associate professor in the computer science department at USC.”But FPGAs have historically been so hard to program that it’s been very hard and expensive to use these advantages. People say, ‘good idea, but…’. We think the new work we report will clear away a significant number of these problems -will kick a lot of ‘but,'” she said.
Both of the papers that will be presented at the June 2-6 40th Design Automation Conference in Anaheim, California apply sophisticated new compilation tools to configure FPGAs. Hall worked with Pedro Diniz, an ISI research associate and research assistant professor in the computer science department at USC, and USC graduate students.
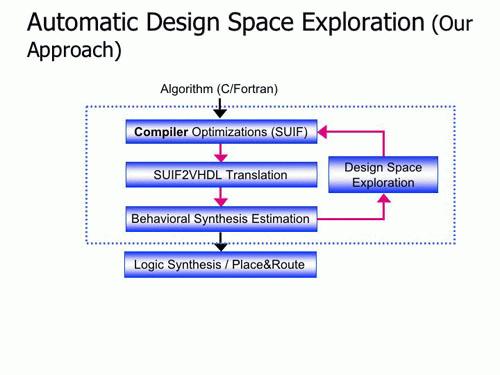
One of the papers, by Hall, Diniz and graduate student Heidi Ziegler, describes analysis techniques to automatically translate programs written in C, a standard language widely used for conventional computers, into pipelined FPGA designs.
The other, by Hall, Diniz and graduate student Byoungro So, shows how what has long been a painfully slow trial and error process to fit the demands of an application to the characteristics of the software in optimal fashion can be automated.
“Together, these two techniques offer a low-cost, high-speed bridge from existing application software to the FPGA platforms,” Hall said.
“The key innovation in our work results from borrowing and adapting analysis and transformation techniques used in conventional multiprocessor systems.” Hall explained.
“Historically, these techniques have not been used in tools that synthesize hardware designs. When our higher-level analysis is combined with the strengths of synthesis tools, such as providing estimates of the characteristics of the resulting design, it becomes possible to automatically explore a collection of hardware designs, all based on a single high-level description of the algorithm.”
“We believe that with further development, this work and near-term follow-on will make FPGAs far more attractive options for many computer users.”
Hall said the “automated design space exploration” techniques described in the second paper would be useful in optimizing applications to all hardware, not just FPGAs.
“If you are trying to implement an application on a platform,” she explains, “you are always dealing with alternatives. You always different routes for achieving a result with the resources on the chip. For example, you need four sums. Do you want to have a single adder do it in four cycles, or do you want to exploit parallelism and have four adders do it at once?”
Traditionally, Hall said, the consequences of such decisions had to be worked out by hand, with assumptions verified by synthesis tools, but “that can take hours or days.” And since each stage of the design depends on the previous decisions, the entire design space exploration process can be much longer, perhaps weeks to months for relatively simple designs.
Old and new: Classic programming technique (top) repeats a simple loop. Improved automated system saves time by quickly eliminating worst options.
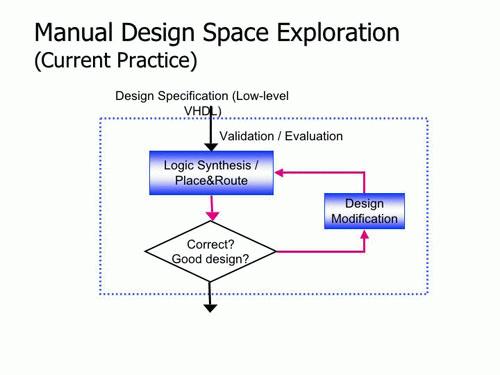
To optimize software in this way for fixed-property chips, such a time penalty is acceptable. “But if you have to in effect do a custom redesign of the software for each application to take advantage of FPGA flexibility,” said Hall, “the potential usefulness of that flexibility is greatly reduced.”
The solution described doesn’t eliminate the task of fitting software to the chip, but it speeds it up by automatically eliminating most of the worst options. “the result is not perfect,” said Hall, “we estimate the performance is within a factor of two of hand-design. But we believe we can improve on that — and we have observed reductions in design time to be on the order of a factor of 100 or more.”
Hall, Diniz, and their collaborators have been developing FPGA programming under a program at ISI called Design Environment For Adaptive Computing Technology (DEFACTO, funded by the Defense Advanced Research Projects Agency (DARPA), and an ongoing project called SLATE (Compiler- Driven Design-Space Exploration for Heterogeneous Systems-on-a-Chip) funded by the National Science Foundation (NSF).
Published on June 2nd, 2003
Last updated on June 11th, 2024







