


By using technology developed for natural language processing, the researchers can predict how viruses might evolve (PHOTO CREDIT: Mingxi Cheng)
The year is 2020; a deeply misunderstood pathogen is traveling all over the world, infecting people wherever it goes. As it bounces from one corner of the planet to another, it mutates, leaving experts racing to stay ahead of the problem.
But the pathogen is not COVID-19. It’s misinformation — much like the QAnon conspiracy theories that helped undermine our country’s faith in democracy just a few months ago.
In some ways, genetic mutations and rumors aren’t so different. In fact, that realization was the premise for some exciting new research published in Nature Scientific Reports. The work might actually help to stop the next pandemic or biological attack before they even start.
Three researchers at the USC Viterbi School of Engineering — Mingxi Cheng, a Ph.D. student, Shahin Nazarian, associate professor of electrical and computer engineering, and Paul Bogdan, the Jack Munushian early career chair and associate professor of electrical and computer engineering — had a key insight: an algorithm that identifies how online rumors mutate into full-blown fake news could be retrained and reclassified to detect the next mutation of viruses like COVID-19.
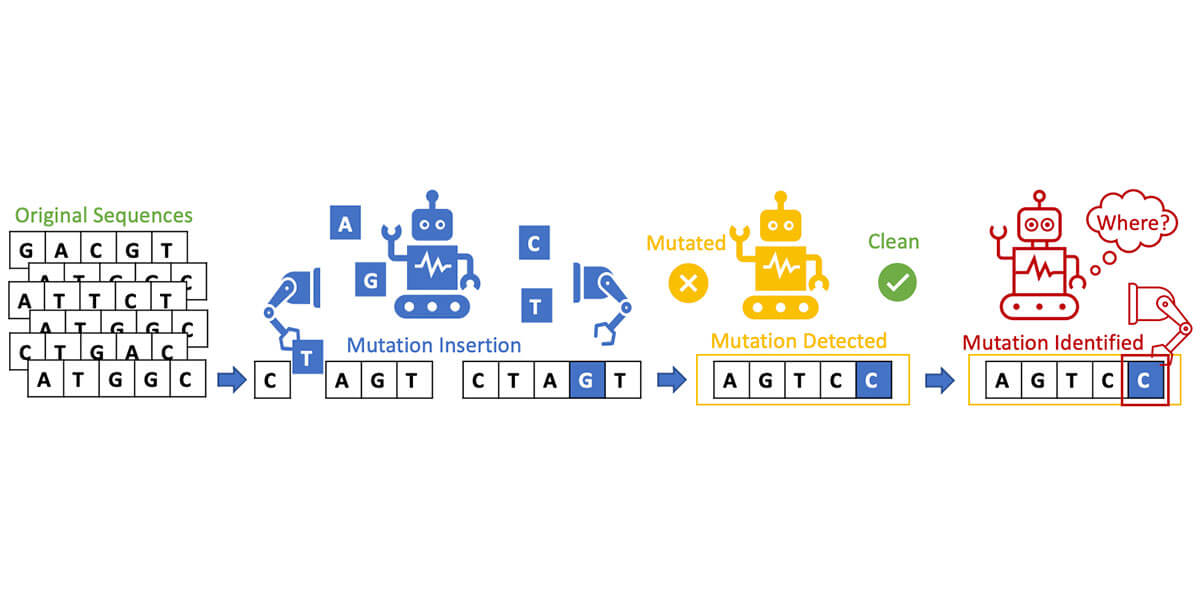
DNA, like language, is written out using a series of letters – A, C, G and T. For some time now Bogdan’s research group has been developing algorithms to identify false or altered language online – important work in today’s world of disinformation. These types of natural language processing algorithms look at a sentence and catchwords that have been altered by a bad actor. Could they also look at a DNA sequence and do the same thing with the billions of letters in that code?
“First, we built a generative algorithm that ever so slightly altered language in a sentence,” Cheng said. “We then built a discriminative algorithm to look at the altered language and catch any false or altered statements.” But there is much more to it than just that.
“This inter-disciplinary research shows new potentials for natural language processing models…Maybe the language of humans is not so different from the language of genes after all.” – Mingxi Cheng
For a discriminative algorithm to truly work, it can’t just identify misinformation. It has to be able to learn how misinformation is generated in the first place. Cheng compares this to Frank Abagnale – a real-life forger turned world-class FBI agent made famous by Leonardo DiCaprio’s portrayal of him in the movie “Catch Me If You Can.” Abagnale was the best at what he did because he came from that world. He understood how forgers thought and knew the strategies they used. “The best discriminative algorithms are ones that don’t just know what rumors look like,” Cheng said. “They actually can learn how rumors are generated in the first place.”
After taking all of this into consideration, the team took their new model and had it look at DNA which had a few altered letters in the sequence. The model quickly and accurately identified where and how changes had been made to DNA. No matter where, or how, or how slightly DNA was altered by the researchers, their model could identify it.
Now, you might be thinking this isn’t such a big deal. We already know the genetic code for nearly everything on the planet, so why do we need an algorithm to tell us when something has been changed? Can’t we just compare a suspicious sequence to the original quite easily?
The first answer to that question is straightforward enough: speed. Bogdan and Cheng’s model could, theoretically, be easily built into existing DNA sequencers and give them the ability to identify the culprit DNA. This means “bad” DNA could be caught quickly and cheaply by anyone who has a sequencer.
But the second answer to that question is the really big one. What these researchers have done is in fact just the first step in something that could have far more reaching implications on our species and our planet – especially in our post-COVID world. “Our next step is to try to enhance our model to the point where we can look at the genetic makeup of a virus and predict where and how dangerous mutations will occur in the future,” said Bogdan, the Jack Munushian Early Career Chair. With that knowledge, vaccines could one day be developed for viruses that haven’t even evolved yet.
The team’s work in this area is truly uncharted territory. No such model with that level of accuracy has ever been developed and if successful it would represent a totally new tool of medicine.
Indeed, if we had such technology it might mean an end to pandemics as we know them. “This truly inter-disciplinary research shows new potentials for natural language processing models and provides a novel angle for problems involving mutations in gene sequences. Maybe the language of humans is not so different from the language of genes after all,” Cheng said.
Published on April 6th, 2021
Last updated on May 16th, 2024






