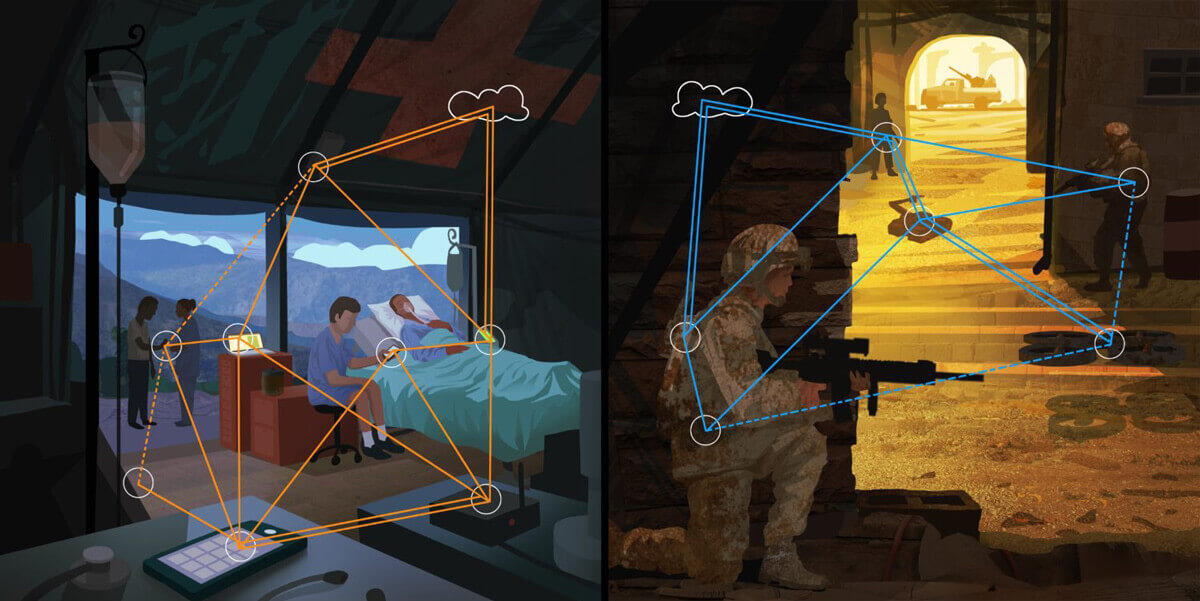
Artist Tim Szabo’s rendition of coded computing in action.
Today, we have access to more information than ever before. Countless sensors are taking in data about temperature, movement, density, speed, and more – from all over the world.
But just HAVING that information is only half the battle. In fact, the sheer volume of data we’re presented with can be overwhelming. Without a system in place to process this flood of data and make sense of it (quickly!) having it around doesn’t do much.
Case in point: Imagine you are in a remote village as part of a medical group whose goal it is to identify the spread of a communicable disease. You have access to machine learning software that runs on a central cloud and can automatically classify a disease based on analyzing a short video of the patients eyes and throat.
Your team could, presumably, send thousands of videos from different patients in different parts of the region to the cloud and map out a path for the disease spreading at speeds and efficiencies never seen before. The challenge you face is one that has been plaguing mankind for decades: poor cell phone data connectivity.
With poor connectivity, uploading large data sets to the cloud is infeasible. But what if a large collection of edge devices (devices that are near the user, at the edge of network) can collaboratively process the videos using computing within each device, along with intermediate networking nodes (in this case, maybe a hospital tent)? That would achieve the same goal without relying entirely on the cloud.
Three professors in the Ming Hsieh Department of Electrical Engineering are working to make this vision come true. Salman Avestimehr (Principal Investigator), Murali Annavaram, and Bhaskar Krishnamachari were recently awarded a $4.2 million contract from DARPA under its new Dispersed Computing program. They are creating a USC-centered testbed to mimic the poor connectivity regions, large data set generation and complex algorithmic execution on small computer devices.

From Left: Murali Annavaram, Salman Avestimehr (Principal Investigator), and Bhaskar Krishnamachari. Photo Credit: USC Viterbi
Their project is called “adaptive pricing and coding (APaC) for dispersed computing.” In other words, processing massive amounts of data quickly and cost-effectively and turning information into knowledge that can be acted on.
At the heart of this problem lie networks themselves. We currently know how to design networks that can do one of two things very well: communication (data transfer) or computation. They can be used to share information, or to make computational analyses of data.
“The challenge we’re trying to solve through this DARPA grant is how to design a smart network that can do both communication and computation effectively,” Avestimehr says.
Avestimehr and his team have designed two innovative approaches to address this challenge. The first approach, named “coded computing,” brings tools from coding theory into the domain of large-scale distributed computing. Traditionally, coding theory is an integral part of making communications efficient by enabling error correction and increasing the data rate. Avestimehr’s team is working on a transformative framework that applies coding theory to distributed computing. The key idea is to use concepts from coding theory to inject “coded” redundant computations into a network to make computing efficient, scalable, and resilient.
Coding theory must be heavily adapted to work for such dispersed computing networks, and no one currently knows how to use it in this way. If our professors can find a way to effectively apply coding theory to dispersed computing networks, we will have taken a huge step forward in our ability to quickly and reliably analyze data.
The goal of the APaC project is to turn information that must be interpreted into knowledge that can be acted on. And if knowledge is power, that’s a very good thing indeed.
The second approach, led by Krishnamachari utilizes tools from optimization and market design to develop decentralized and efficient algorithms for scheduling computation tasks in a large network and allocating sufficient resources to them. According to Krishnamachari, “Our proposed techniques for resource allocation are inspired in part by ideas from market economics. We anticipate that they will allow the scheduling of computation and communication to happen even in dynamically changing networks in which links may vary in quality over time, for example due to outages in wireless connectivity.”
They plan to make theory meet practice using a testbed of highly heterogeneous and small form factor compute nodes that act as edge devices. Imagine dozens of Raspberry PIs, Arduinos, or USB-sized Compute Sticks that are connected as a network of edge devices. Each device in turn may be augmented with different sensors that monitor the environment.
These edge nodes + sensors are connected by a collection of routers and access points, an effort that will be led by Annavaram. (Don’t worry, no personal information is being collected!)
The campus-wide testbed will also be supported by the recently created Viterbi Center for Cyber-Physical Systems and the Internet of Things (CCI). According to Annavaram, “the challenge is to make the entire testbed with myriads of heterogeneous capabilities at each edge node appear as a plain old computer so that software developers won’t drown in complexity. Running an application on the testbed must be as simple as running it on any generic cloud server.” The team will use this testbed to apply their algorithms on a real-world computing scenario that has broad applications in public safety, security and surveillance, robotics, and autonomous driving.
If successful, coded computing has the potential to bring many industries on the verge of breaking out into the mainstream. “The most affected industries are ones where the data is gathered near the user, at the edge of the network, and that also has to be processed quickly right there,” Avestimehr explains.
That remote, disease stricken village is a perfect example of just such an industry. A network of phone cameras are near the users, must bring in a lot of information about patients quickly, and process that information right then and there without sending it to some other location for analysis.
Ultimately, the goal of the APaC project is to turn information that must be interpreted into knowledge that can be acted on. And if knowledge is power, that’s a very good thing indeed.
Published on June 28th, 2017
Last updated on October 4th, 2024